Um die Verfügbarkeit zu erhöhen ist die Methode des Clusterns, also Verbinden von zwei oder mehr baugleichen Geräten zu einer Einheit, eine erprobte Technik. Auch bei den Juniper SRX Firewalls steht diese Technologie zur Verfügung. Ich habe einen Sonntag Nachmittag zugebracht dies mit zwei SRX 210 Geräten auszuprobieren.
Schritt 1Als erstes sollten wir das JUNOS Betriebssystem auf den letzten Stand bringen. Das ist zum heutigen Datum JUNOS 9.6 Release 2. Speziell wurden hier etliche Fehler in Zusammenhang mit Clustering beseitigt. Da ich davon ausgehe, dass jeder mit dem Upgrade-Vorgang vertraut ist, überspringe ich diesen Teil.
Schritt 2Nicht zwingend notwendig aber meiner Meinung nach Best Practice: Wir beginnen mit der Factory-Default Konfiguration. Durch das Clustering bekommen wir ohendies andere Interface-Namen sodass sich bestehende Konfigurationen nur bedingt übernehmen lassen. Jedenfalls weiß man was man hat, wenn man von einem definierten Punkt ausgeht.
Die Auslieferungskonfiguration lässt sich mit in drei einfachen Schritten herstellen:
- load factory-default
- set system root-authentication plain-text-password sowie Eingabe des Root-Kennworts
- commit
Schritt 3Als nächstes müssen wir die beiden Geräte verkabeln. Welche Ports verbunden werden müssen ist von Gerät zu Gerät unterschiedlich. Das JUNOS Handbuch verrät die
Belegung für jeden Typ. Hier z.B. die entsprechende Schaltung für die SRX 210:
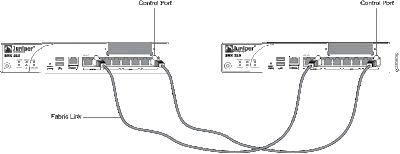
Es gibt dabei zwei Verbindungen: Der Control Link dient zum Austausch des Heartbeat Signals, zum Abgleich der Konfiguration sowie dem Abgleich der Realtime Objects (RTO). RTOs sind z.B. aktive Sessions, NAT Tabellen usw.
Der Fabrik Link kommt Active-Active Konfigurationen zum Tragen. Wenn nämlich Daten in Knoten 0 eingehen und über Knoten 1 hinausgeschickt werden, werden sie über den Fabriklink von Knoten 0 zu Knoten 1 weitergeleitet. Daher muss hier auch immer eine Gigabit-Verbindung verwendet werden um die entsprechende Kapazität zur Verfügung zu stellen.
Schritt 4Jetzt aktivieren wir den Cluster-Modus. Zuerst auf dem zukünftigen Knoten 0, danach auf Knoten 1. Als Cluster ID stehen die Zahlen 1 bis 15 zur Verfügung. Sollten mehrere Cluster in einem Netzwerk verwendet werden müssen diese verschiedene Cluster-IDs haben. Dies deswegen weil die Cluster-ID zur Bildung von (virtuellen) MAC-Adressen der redundanten Interfaces herangezogen werden und es sonst zu uneindeutigen MAC-Adressen kommen könnte.
Wichtig: Die folgenden Befehle werden im Operations und nicht wie man glauben könnte, im Configuration-Mode, abgesetzt:
- Auf Knoten 0: set chassis cluster cluster-id 1 node 0 reboot
- Der Knoten 0 startet neu, wir warten ab bis er den Reboot Vorgang abgeschlossen hat
- Auf Knoten 1: set chassis cluster cluster-id 1 node 1 reboot
- Der Knoten 1 startet neu, wir warten ab bis er den Reboot Vorgang abgeschlossen hat
Nach kurzer Zeit sollte das HA Lämpchen auf beiden Geräten Grün leichten. Dies ist das Zeichen dafür, dass ich die Knoten gefunden und ihre Konfiguration abgeglichen haben. Wir können dies Überprüfen, indem wir auf einem der beiden Knoten den Befehl
show chassis cluster status absetzen:
Cluster ID: 1Node name Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1 node0 1 primary no no
node1 1 secondary no noWeiters müssen wir beachten, dass sich nun die Bezeichnungen der Interfaces geändert haben. Auf Knoten 0 bleibt alles so wie es ist, auf Knoten 1 hat es aber eine Verschiebung gegeben. Das ge-0/0/0 Interface heißt jetzt ge-2/0/0, fe-0/0/2 nun fe-2/0/2 usw. Eine genaue Liste wie die Interface-Namen sich verändern liefert
dieser Teil des JUNOS-Handbuchs.
Schritt 5Die Interfaces des Fabrik-Links müssen in der Konfiguration angegeben werden. Wir tun dies per
set interfaces fab0 fabric-options member-interfaces ge-0/0/1
set interfaces fab1 fabric-options member-interfaces ge-2/0/1Schritt 6Es gibt einige Konfigurationselemente die auf den jeweiligen Knoten anders sind. Z.B. der Hostname des Knotens oder die IP-Adresse des Out of Band Management Interfaces. Letzteres fehlt bei der SRX 210, wir müssen uns also nur um den eindeutigen Hostnamen kümmern. Man stellt dies mit zwei Apply-Gruppen ein:
set groups node0 system host-name node0 set groups node1 system host-name node1Um die Apply-Gruppen anzuwenden setzen wir noch ab:
set apply-groups "${node}"Wir können nun commiten.
Schritt 7Wir können uns nun der Konfiguration der redundanten Interfaces zuwenden. In unserer simplen Konfiguration möchte ich folgendes herstellen:

Wir benötigen hier zwei redundante Interfaces: Ein Trust und ein Untrust Interface. In der Praxis würde man hier auch jeweils zwei Switches verwenden um sich nicht noch einen Single-Point-of-Failure einzuhandeln. In unserem einfachen Fall ist das aber völlig ausreichend. Wir verwenden dafür die Interfaces ge-0/0/0 und ge-2/0/0 und fe-0/0/2 und fe-2/0/2.
Damit beide Interfaces unabhängig voneinander ein Failover durchführen können, werden wir das redundante Interface in jeweils eine eigene Redundanzgruppe einbringen.
Zuerst müssen wir dem System bekannt geben, dass wir zwei redundante Interfaces benötigen:
set chassis cluster reth-count 2Danach legen wir die Konfiguration der einzelnen Redundanzgruppen an. Ich möchte das immer der Konten 0 aktiv ist solange möglich, aber ohne automatisches Failback. Weiters soll ein Failover ausgelöst werden, wenn eines der beteiligten Interfaces down geht und es aber gerade aktiv ist.
set chassis cluster redundancy-group 1 node 0 priority 100set chassis cluster redundancy-group 1 node 1 priority 50set chassis cluster redundancy-group 1 interface-monitor ge-0/0/0 weight 255set chassis cluster redundancy-group 1 interface-monitor ge-2/0/0 weight 255set chassis cluster redundancy-group 2 node 0 priority 100set chassis cluster redundancy-group 2 node 1 priority 50set chassis cluster redundancy-group 2 interface-monitor fe-0/0/2 weight 255set chassis cluster redundancy-group 2 interface-monitor fe-2/0/2 weight 255Das Gewicht 255 bei den Interfaces verdient noch etwas Beachtung. Unter Umständen möchte man ein Failover nicht schon bei einem Interface sondern erst wenn zumindest zwei oder mehrer Interfaces ausgefallen sind. Damit kann man jedem Interface ein individuelles Gewicht geben. Überschreitet die Summe der Gewichte der ausgefallenen Interfaces 255, wird ein Failover ausgelöst. Da uns schon ein Interface ausreicht, vergeben wir hier jeweils 255.
Jetzt konfigurieren wir die beiden Redundanzinterfaces reth0 und reth1:
set interfaces reth0 redundant-ether-options redundancy-group 1set interfaces reth0 unit 0 family inet address 192.168.0.1/24set interfaces reth1 redundant-ether-options redundancy-group 2set interfaces reth1 unit 0 family inet dhcpDas Untrust-Interface soll seine IP-Adresse per DHCP vom Provider bekommen. Beim Trust Interface legen wir 192.168.0.1/24 fest.
Danach binden wir die physischen Interfaces an das jeweilige redundante Interface:
set interfaces ge-0/0/0 gigether-options redundant-parent reth0set interfaces ge-2/0/0 gigether-options redundant-parent reth0set interfaces fe-0/0/2 fastether-options redundant-parent reth1set interfaces fe-2/0/2 fastether-options redundant-parent reth1Zum Schluss benötigen wir noch ein paar Firewall-spezifische Konfigurationen:
Wir fügen die redundanten Interfaces jeweils einer Zone hinzu und erlauben den notwendigen eingehenden Traffic:
set security zones security-zone trust interfaces reth0.0 host-inbound-traffic system-services allset security zones security-zone untrust interfaces reth1.0 host-inbound-traffic system-services dhcpWeiters müssen wir noch Source NAT aktivieren:
set security nat source rule-set outgointNAT from zone trustset security nat source rule-set outgointNAT to zone untrustset security nat source rule-set outgointNAT rule rule1 match source-address 0.0.0.0/0set security nat source rule-set outgointNAT rule rule1 match destination-address 0.0.0.0/0set security nat source rule-set outgointNAT rule rule1 then source-nat interfaceDer Client muss derweil statisch konfiguriert werden, einen DHCP-Server auf der SRX einzurichten erspare ich mir. :-)
Das ganze noch commiten und schon ist unser Cluster fertig. Bei einem Link-Fehler geht 1 Ping verloren, beim Ausfall einer ganzen Box dauert es ca. 8 Pings bis das System sich wieder stabilisiert hat.
Viel Spaß beim Nachmachen!






